Lire, écrire … A l’ère numérique – 1 – La lecture aujourd’hui
 L’environnement numérique est depuis quelque temps accusé de tous les maux, et surtout d’avoir « tué » la lecture, notamment chez les jeunes. En perturbant l’attention des lecteurs avec des liens hypertextes et des notifications diverses (mails, réseaux sociaux, SMS et même coups de fils) sur les ordinateurs et terminaux mobiles, la lecture numérique perd l’intensité de l’’attention profonde’ qui permet de s’investir pleinement dans un texte et de comprendre un document. Cette dernière se transforme alors en ‘hyperattention’ et se disperse en suivant plusieurs fils d’information. C’est ce que démontre Katherine Hayles, professeur à l’Université de Duke, citée dans le séminaire de l’IRI « Ecologie de l’attention » organisé par Bernard Stiegler et Igor Galligo en 2013-2014 au Centre Pompidou. J’avais évoqué cette controverse dans le post « Livres/écrans : quelle hybridation pour la bibliothèque du 21e siècle » : il apparaissait que le problème ne résidait pas dans l’opposition ‘papier/numérique’, puisque les liseuses à encre électronique (e-ink) permettent l’attention profonde, mais dans la dualité entre culture des écrans et culture du livre selon le psychanalyste Serge Tisseron. Dans la culture du livre le rapport au savoir est vertical (auteur/lecteur), tandis que devant les écrans, les lecteurs se trouvent devant un accès plus diversifié et horizontal.
L’environnement numérique est depuis quelque temps accusé de tous les maux, et surtout d’avoir « tué » la lecture, notamment chez les jeunes. En perturbant l’attention des lecteurs avec des liens hypertextes et des notifications diverses (mails, réseaux sociaux, SMS et même coups de fils) sur les ordinateurs et terminaux mobiles, la lecture numérique perd l’intensité de l’’attention profonde’ qui permet de s’investir pleinement dans un texte et de comprendre un document. Cette dernière se transforme alors en ‘hyperattention’ et se disperse en suivant plusieurs fils d’information. C’est ce que démontre Katherine Hayles, professeur à l’Université de Duke, citée dans le séminaire de l’IRI « Ecologie de l’attention » organisé par Bernard Stiegler et Igor Galligo en 2013-2014 au Centre Pompidou. J’avais évoqué cette controverse dans le post « Livres/écrans : quelle hybridation pour la bibliothèque du 21e siècle » : il apparaissait que le problème ne résidait pas dans l’opposition ‘papier/numérique’, puisque les liseuses à encre électronique (e-ink) permettent l’attention profonde, mais dans la dualité entre culture des écrans et culture du livre selon le psychanalyste Serge Tisseron. Dans la culture du livre le rapport au savoir est vertical (auteur/lecteur), tandis que devant les écrans, les lecteurs se trouvent devant un accès plus diversifié et horizontal.
D’autre part, comme le démontre le neuropsychologue Stanislas Dehaene dans la vidéo 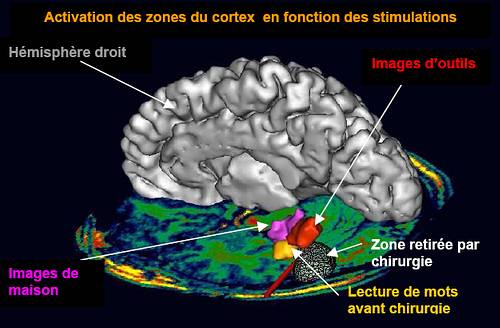 « cerveau et lecture » à l’Académie Royale de Belgique, la mise en place de la lecture est apparue assez tard dans l’histoire de l’humanité : au cours de l’évolution, la plasticité du cerveau a permis de ‘recycler’ une aire neuronale pour la consacrer à l’activité du décodage de signes abstraits (mots). L’imagerie cérébrale a permis d’identifier cette zone et notamment le rôle du cortex temporal gauche, la « boite à lettre » du cerveau, dans cette activité. Les neurones de cette région ne répondent pas lorsque la personne est illettrée. Si notre système cognitif a pu s’adapter à un moment de notre histoire pour produire l’activité de lecture (et d’écriture comme mémoire externe), il devrait être capable de s’adapter aussi à l’environnement numérique.
« cerveau et lecture » à l’Académie Royale de Belgique, la mise en place de la lecture est apparue assez tard dans l’histoire de l’humanité : au cours de l’évolution, la plasticité du cerveau a permis de ‘recycler’ une aire neuronale pour la consacrer à l’activité du décodage de signes abstraits (mots). L’imagerie cérébrale a permis d’identifier cette zone et notamment le rôle du cortex temporal gauche, la « boite à lettre » du cerveau, dans cette activité. Les neurones de cette région ne répondent pas lorsque la personne est illettrée. Si notre système cognitif a pu s’adapter à un moment de notre histoire pour produire l’activité de lecture (et d’écriture comme mémoire externe), il devrait être capable de s’adapter aussi à l’environnement numérique.
C’est ce qu’explique Christian Jarrett dans le post de Wired «The Internet isn’t ruining your teenager’s brain ». Malgré les prophètes de mauvais augure qui nous présentent une génération d’adolescents perturbés et distraits, internet et les usages numériques pourraient avoir une action positive sur l’esprit des jeunes en les rendant plus sociaux. Et même si une très faible minorité subit une addiction, par exemple aux jeux vidéo, la plasticité du cerveau devrait permettre d’inverser ce processus à l’âge adulte …

D’ailleurs la lecture numérique a d’autres avantages recensés dans le post La lecture sur l’internet rend-elle idiot? Pas si sûr! : survoler un article pour en extraire les informations pertinentes, etc. Comme le dit l’écrivain espagnol Lorenzo Silva, cité dans un article d’Actualitté, Internet est « le grand texte du peuple qui ne lit pas ». Si les gens ne lisent plus comme avant, internet n’est rien d’autre que du texte (de moins en moins …) et il faut s’assurer de la qualité de ce grand texte !
Il existe aussi un certain nombre d’outils qui permettent de retrouver sur les écrans la tranquillité de la page imprimée. Evernote ou Readability suppriment tous les parasites (publicités, annonces diverses, renvois, etc.) qui polluent les sites web pour donner accès à une lecture ‘zen’ ou décalée ![]() Mais, sauf si on déconnecte le terminal, on n’échappera pas aux ‘distractions’ en ligne : hypertexte, notifications …
Mais, sauf si on déconnecte le terminal, on n’échappera pas aux ‘distractions’ en ligne : hypertexte, notifications …
Il est vrai que la place de la lecture a beaucoup régressé dans les activités culturelles des Français, au profit bien sûr des médias audiovisuels et interactifs : télévision, vidéos, jeux vidéo, musique, etc. La lecture de vingt livres ou plus par an est passée, d’après les enquêtes sur les pratiques culturelles des Français, de 28 personnes sur 100 en 1973 à 16 en 2008, et surtout de 41 à 16 pour les 18-24 ans ! Un enquête plus récente d’IPSOS citée dans Actualitté comparaît les données de 2014 sur le comportement des lecteurs avec celles de 2011 : si la proportion des lecteurs au format papier a légèrement diminué passant de 70% à 69%, les lecteurs au format numérique sont passé de 8 à 11% en trois ans ! La pratique de la lecture n’a donc pas disparu, mais se transforme …
Au niveau mondial, l’édition numérique serait en hausse et devrait progresser de près de 20% sur la période 2013-2018 d’après le « Global e-book market ».
La fréquentation des bibliothèques reflète d’ailleurs cette tendance : l’inscription en bibliothèque a progressé entre 1973 et 2008 : on est passé de 13 Français de 15 ans et plus sur 100 en 1973 à 18 inscrits en 2008 et surtout de 18 à 31 pour les 18 – 24 ans ! Il est intéressant de corréler ces données avec les pratiques de lecture de livres : il semblerait que les jeunes ne fréquentent pas les bibliothèques uniquement pour lire des livres ! En revanche, en ce qui concerne les bibliothèques universitaires, l’étude réalisée par l’Université de Toulouse en 2012 montre que la relation entre l’utilisation de la documentation des BU et la réussite aux examens des étudiants est bien réelle. «… le lien entre emprunts et réussite est très fort : la probabilité de valider son semestre est beaucoup plus élevée pour les étudiants empruntant beaucoup d’ouvrages que pour ceux en empruntant peu …». 
Mais revenons à la lecture numérique. Si les neurosciences cognitives n’ont pas encore tranché sur les différences entre la lecture « papier » et la lecture « écran », cette dernière n’a pas que des inconvénients : elle permet aussi un partage « social » des commentaires et annotations, mais surtout la ‘fouille de données’, en anglais le TDM (text and data mining). C’est ce que souligne Christophe Perales dans son post « Infini de la lecture : de Cassiodore au text et data mining » en comparant l’arrivée du numérique avec la mutation qu’a connu le livre au début du IIIe siècle en passant du volumen au codex. Cette mutation a complètement changé les rapports des lecteurs à l’écrit bien plus que l’invention de l’imprimerie ! « le codex va ouvrir la possibilité de constituer des tables des matières, des index, de confronter bien plus commodément, et quasi simultanément, des passages différents, à l’intérieur d’un même livre ou entre plusieurs ouvrages. […] Une innovation matérielle peut donc avoir des conséquences intellectuelles importantes. »
Le web nous a fait retrouver la possibilité de plusieurs lecteurs d’intervenir sur un même texte pour le commenter à travers des annotations qui existaient déjà au Moyen-Age ! Mais c’est la fouille de contenu qui représente la pratique la plus disruptive apportée par le numérique à la lecture. L’utilisation de ces ‘mégadonnées’ à partir des textes et des corpus grâce aux outils des humanités numérique va changer complètement le rapport au savoir pour les chercheurs. Évidemment, un problème juridique existe encore pour l’accès complètement libre à ces textes. Mais ce qui change complètement la donne dans cette innovation ce n’est plus l’ »interface neuronal » entre l’œil et le système cognitif qui décrypte ces signaux, mais un dispositif automatique, un robot qui « lit » et traite ces volumes très importants d’information. Même si en fin de compte, ce sont des humains qui donnent un sens à cette opération … ! 
Pour aller plus loin
Ferrando, Sylvie. - Compte rendu de l’ouvrage de Stanislas Dehaene Les neurones de la lecture, introd. de J.P Changeux. Ed. Odile Jacob, 2007. – Relais d’Information sur les sciences de la cognition (RISC)-CNRS, 2007 (pdf).
Ministère de la culture et de la communication. - Enquête sur les pratiques culturelles des Français : évolution 1973-2008. – Département des enquêtes, de la prospective et des statistiques.
Emprunt en bibliothèques universitaires et réussite aux examens de licence. – Étude lecture V 21 – Université de Toulouse, décembre 2012
Keim, Brandon. – Why the smart reading device of the future may be … Paper. – Wired, 05/01/14
Helmlinger, Julien. – Comportement et évolution de la lecture chez les Français. – Actualitté, 13/03/14
L’attention et la dynamique des écrans et images virtuelles in Ecologie de l’Attention – IRI – Centre Pompidou, 02/04/14 – Vidéo Lignes de temps
Jahjah, Marc. – Qu’est-ce que la lecture sociale ? - INAGlobal, 23/07/14
Lire à l’écran : (re)tournons à la page. – Site de François Jourde, 06/08/14
Est-ce que le livre numérique tue vraiment la lecture? – Slate, 14/08/14
Delarbre, Clémence. – La bibliothèque du futur sera-t-elle sans livres ? – Rue 89, 14/08/14
Des livres, des lecteurs, des lectures. – Le dernier blog, 26/08/14
Perales, Christophe. - Infini de la lecture : de Cassiodore au text et data mining. -BibliOpen – Blog Educpros, 04/09/14
Tags: Ebooks, lecture, Savoir, Sociologie