Big data, open data, protection des données personnelles : où en sont la science et l’utilisation des données ?
 Les données sont partout, aussi bien dans la vie quotidienne que dans la recherche. Une nouvelle discipline, la science des données, mobilise des experts en mathématique et informatique pour analyser et traiter ce ‘pétrole’ du 21e siècle à coup d’algorithmes et de logiciels d’intelligence artificielle. Tout au long de la journée, des ‘bots’ (petits logiciels d’IA) et des objets connectés les recueillent grâce à des capteurs. On y accède librement, grâce aux dispositifs d’open data, que ce soit dans la ville intelligente (smart city) ou au niveau de la ‘science ouverte’. Les GAFA et autres géants du net se disputent nos données personnelles en investissant des milliards pour les exploiter. Quel droit et quelles réglementations doit-on mettre en place pour protéger ces données tout en profitant de ces nouvelles ressources ?
Les données sont partout, aussi bien dans la vie quotidienne que dans la recherche. Une nouvelle discipline, la science des données, mobilise des experts en mathématique et informatique pour analyser et traiter ce ‘pétrole’ du 21e siècle à coup d’algorithmes et de logiciels d’intelligence artificielle. Tout au long de la journée, des ‘bots’ (petits logiciels d’IA) et des objets connectés les recueillent grâce à des capteurs. On y accède librement, grâce aux dispositifs d’open data, que ce soit dans la ville intelligente (smart city) ou au niveau de la ‘science ouverte’. Les GAFA et autres géants du net se disputent nos données personnelles en investissant des milliards pour les exploiter. Quel droit et quelles réglementations doit-on mettre en place pour protéger ces données tout en profitant de ces nouvelles ressources ?
La science des données
La science des données (en anglais data science) est une nouvelle discipline qui s’appuie sur des outils mathématiques, de statistiques, d’informatique (cette science est principalement une « science des données numériques »4) et de visualisation des données. Le premier objectif du « data scientist » est de produire des méthodes (automatisées, autant que possible) de tri et d’analyse de données de masse et de sources plus ou moins complexes ou disjointes de données, afin d’en extraire des informations utiles ou potentiellement utiles. Pour cela, le « scientifique des données » s’appuie sur la fouille de données, les statistiques, le traitement du signal, diverses méthodes de référencement, l’apprentissage automatique et la visualisation de données. Il s’intéresse donc à la classification, au nettoyage, à l’exploration, à l’analyse et à la protection de bases de données plus ou moins interopérables. (Wikipedia).
Comme l’énonce Stéphane Mallat, dans sa leçon inaugurale pour la création d’une chaire Science des données au Collège de France, « cette discipline s’inscrit au cœur de la problématique scientifique : extraire de la connaissance des données empiriques qui se trouvent à la base de toutes les sciences. On est dans une évolution extraordinairement rapide qui inclut toutes les sciences qui viennent avec leurs propres données. »
Les deux principaux traitements sont la modélisation et la prédiction. L’enjeu en est la généralisation. Dans ce domaine, l’informatique a une avance considérable sur les mathématiques. Elle permet à partir d’un exemple qu’on connaît, d’extrapoler pour les exemples qu’on ne connaît pas. Elle s’appuie sur un très grand nombre de variables (ex : millions de pixels dans une image). 
En ce qui concerne la gestion des données scientifiques, les professionnels de l’information, dans les bibliothèques de recherche par exemple, peuvent être de précieux collaborateurs pour les chercheurs. Comme le soulignent Ayoung Yoon et Theresa Schulz dans leur article du College & Research Libraries « les bibliothèques universitaires se sont activement impliquées dans les services des données de la recherche : des services qui portent sur l’ensemble du cycle de vie des données comprenant le plan de gestion, la curation numérique (sélection, conservation, maintenance et archivage), la création de métadonnées et la conversion. ». Un nouveau service, le TDM ‘Text and Data Mining’ (fouille automatique de texte et de données) a pu être récemment être ajouté grâce à une série d’amendements au droit d’auteur en France, mais aussi au Royaume Uni.
Les données numériques et la « ville intelligente »
Dans la ‘smart city’, le recueil et le traitement des données devraient permettre aux citoyens de bénéficier de services sur mesure. A Toronto, une filiale de Google est en train d’édifier une métropole futuriste dans un quartier défavorisé au bord du lac Ontario. Comme le rappelle Ian Austen dans le New York Times fin décembre « le Premier ministre canadien, Justin Trudeau a promis que ce projet créerait ‘des technologies qui nous aideraient à construire des communautés plus intelligentes, plus vertes et plus inclusives ». Mais pour certains résidents cet enthousiasme doit être tempéré surtout quand il s’agit d’une entreprise connue pour sa collecte et analyse des données. Le projet Quayside sera chargé de capteurs et de caméras de surveillance qui traqueront tous ceux qui habitent, travaillent ou simplement passent dans le quartier. La masse de données recueillie permettra de mieux organiser et définir les besoins de la future ville, que la société appelle d’ailleurs une ‘plateforme’. L’électricité sera fournie par des mini-réseaux de voisinage, basés sur des énergies renouvelables. D’immenses auvents protègeront de la pluie et du soleil d’été et des allées chauffées feront fondre la neige l’hiver ! 
Mais les capteurs dans les bâtiments pourront mesurer le bruit dans les appartements tandis que les caméras et les capteurs extérieurs surveilleront aussi bien la pollution de l’air que le mouvement des personnes et des véhicules dans les carrefours … Comme le fait remarquer Pamela Robinson, professeur de planification urbaine à l’université Ryerson de Toronto « les données vont être recueillies par une entreprise privée et non par une collectivité administrative. Pour le moment rien n’a été annoncé sur qui en aura la propriété ni qui y aura accès. » De même, si Quayside promet des logements à tous les niveaux de revenus, pour le moment la seule entreprise qui a prévu de s’y installer est Google Canada, donc plutôt des jeunes cadres bien payés … D’après cette chercheuse, les données collectées pourraient être utilisées pour limiter ou décourager l’usage, par ailleurs légitime, des espaces publics par des sans-logis, des jeunes ou d’autres groupes …
Bernard Stiegler qui intervenait dans la Cité du Futur, conférence de Maddyness, déclarait « Pour faire des villes intelligentes, essayons d’être intelligent. La nouvelle urbanité, c’est la ville désautomatisée, car la ville automatisée détruit les relations de voisinage ». Citant l’expérience de Plaine Commune (Communauté de 9 communes de Seine Saint-Denis) où il est personnellement impliqué mais aussi des entreprises comme Vinci, Orange et la Caisse des Dépôts, le philosophe a expliqué que cela implique de savoir utiliser ces technologies innovantes avec la population de Seine Saint-Denis pour qu’elle y prenne part, notamment à travers un programme d’économie contributive.
 C’est aussi le point de vue de Florence Durand-Tornare, fondatrice et déléguée générale de l’association Villes Internet dans l’article de Martine Courgnaud-Del Ry dans la Gazette des communes : « Plus de trente « Villes Internet » (hors métropoles) décrivent, parfois depuis longtemps, des dispositifs de mise à disposition de données informatives, techniques, juridiques ou statistiques. Ce qui me paraît significatif, c’est qu’elles ouvrent avant tout des données utiles au citoyen, et pas uniquement celles qui sont attendues par les grands opérateurs dans les zones hyper-urbaines — essentiellement relatives au transport ou à la gestion de l’énergie… Nous remarquons aussi que l’ouverture des données est l’occasion d’organiser des dispositifs participatifs avec les citoyens, qui contribuent parfois activement à choisir les applications utiles aux résidents que la donnée permet de produire. »
C’est aussi le point de vue de Florence Durand-Tornare, fondatrice et déléguée générale de l’association Villes Internet dans l’article de Martine Courgnaud-Del Ry dans la Gazette des communes : « Plus de trente « Villes Internet » (hors métropoles) décrivent, parfois depuis longtemps, des dispositifs de mise à disposition de données informatives, techniques, juridiques ou statistiques. Ce qui me paraît significatif, c’est qu’elles ouvrent avant tout des données utiles au citoyen, et pas uniquement celles qui sont attendues par les grands opérateurs dans les zones hyper-urbaines — essentiellement relatives au transport ou à la gestion de l’énergie… Nous remarquons aussi que l’ouverture des données est l’occasion d’organiser des dispositifs participatifs avec les citoyens, qui contribuent parfois activement à choisir les applications utiles aux résidents que la donnée permet de produire. »
L’adoption du RGPD et la polémique sur la ‘patrimonialisation’ des données personnelles
L’Assemblée nationale examine en ce moment le projet de loi sur la protection des données personnelles « qui adapte notre droit au nouveau cadre juridique européen, composé d’une part, du règlement général de la protection des données (RGPD) et d’autre part de la directive sur les fichiers de police et de justice, qui entreront tous deux en vigueur en mai 2018. ». Ce règlement fixe de nouvelles obligations à toute entreprise exploitant des données : droit de portabilité d’un opérateur à l’autre, droit d’effacement et surtout, consentement explicite.
Une controverse vient de se développer dans la presse après une interview Gaspard Koenig dans Les Echos évoquant le Rapport du mouvement Génération libre vantant les mérites de la commercialisation des données personnelles. Pour G. Koenig « si la data est bien cet « or noir » du 21ème siècle, il n’y a pas de raison de ne pas payer les producteurs – nous – sans laisser aux raffineurs (les agrégateurs et les plates-formes) l’intégralité des revenus liés à l’exploitation des data. » Pour ce philosophe libéral, il y a trois options pour gérer l’accès aux données : mettre en place une « sorte d’agence nationale chargée de mettre des data encryptées à la disposition des entreprises », créer, comme la CNIL et la Commission européenne, des « droits pour les citoyens et des obligations pour les entreprises, avec le risque de judiciarisation excessive de l’économie digitale et d’étouffer l’innovation ». La troisième option qu’il privilégie et « qui peut s’articuler à la précédente, est la patrimonialité des données pour permettre aux entreprises de se les approprier après avoir justement rémunéré les citoyens. ». Cette transaction se ferait à travers « un système de ‘nanopaiements’ qui viendraient créditer ou débiter en continu un compte digital personnel ». Ceux qui refuseraient de céder leurs données seraient obligés de payer les services numériques. Cette idée a été reprise dans une tribune du Monde prônant la ‘monétisation de nos données’, signée par plusieurs personnalités (Bruno Bonnell, Laurence Parisot, Alexandre Jardin, Gaspard Koenig). 
Cette « fausse bonne idée » comme la définissent Serge Abiteboul et Gilles Dowek dans une tribune dans le Monde, a été immédiatement attaquée par un grand nombre de chercheurs et de juristes dans la presse et sur les réseaux sociaux. Pour ces deux chercheurs « Le cas des données numériques est cependant un peu plus complexe que celle de des champs d’orge ou de blé, car qui cultive les données ? Ceux qui les produisent (vous et moi, les géants du Web, les hôtels…), ou ceux qui les entassent et les analysent pour en tirer du profit (ni vous et moi) ? ». Et même une fois la propriété établie, comment les internautes seront-ils assurés que le contrat ne soit pas léonin (accès au service contre ‘open bar’ pour les géants du Net) ? De plus, il n’est pas sûr que ces entreprises soient vraiment intéressées par nos données personnelles, vu qu’à travers le ‘crowdsourcing’, un grand nombre d’internautes produisent déjà du travail sur les données pour une très faibles rémunération. Mais surtout les données personnelles sont avant tout sociales : elles résultent des interactions des internautes entre eux ou avec des entreprises ou institutions (mails, commentaires, profils, etc.). Tristan Nitot dans son post sur Standblog, reprenant la comparaison avec la vente d’un rein, rappelle que déjà le CNNum estimait que « l’introduction d’un système patrimonial pour les données personnelles est une proposition dangereuse ». Comme il est interdit de faire commerce de ses organes (‘indisponibilité’ ou ‘non patrimonialité’ du corps humain), on ne peut séparer l’individu de ses données personnelles, ça serait en faire un objet qu’on peut commercialiser « permettre la patrimonialisation c’est — métaphoriquement — permettre de revendre par appartements son moi numérique, c’est faire commerce de son corps numérique, en quelque sorte, ce qui est interdit en France pour son corps physique, au nom de la dignité humaine. ». De plus, il sera très difficile à un individu de se faire payer vu les difficultés qu’a le fisc à faire payer les GAFA … Le rapport de force ne sera pas du tout en sa faveur …
 Une autre position est celle développée par l’essayiste Evgeni Morozov dans l’émission Soft Power citée par Calimaq dans son post fin octobre. Plutôt que la défense individuelle de la vie privée, Morozov propose de faire des données personnelles un ‘bien public’ et de les faire relever du ‘domaine public’. Il ne pense pas « qu’on puisse régler tous les problèmes que posent les géants du net en utilisant les outils traditionnels de régulation du marché, c’est-à-dire en leur faisant payer des taxes et en mettant en place des lois anti-trust ». Il préconise même d’accélérer le processus d’automatisation et d’analyse des données, car tout n’est pas négatif. Si les cancers pourront bientôt être dépistés grâce aux données, cela ne devrait pas se faire en donnant autant de pouvoir à des entreprises de la Silicon Valley ! Un système dans lequel les données appartiennent à la communauté permet à tout un chacun de se saisir de ces données pour en faire quelque chose, même au niveau local. E. Morozov préconise « un système hybride empruntant à la fois des éléments à la domanialité publique et à la propriété intellectuelle, tout en s’inspirant de certains mécanismes des licences libres ».
Une autre position est celle développée par l’essayiste Evgeni Morozov dans l’émission Soft Power citée par Calimaq dans son post fin octobre. Plutôt que la défense individuelle de la vie privée, Morozov propose de faire des données personnelles un ‘bien public’ et de les faire relever du ‘domaine public’. Il ne pense pas « qu’on puisse régler tous les problèmes que posent les géants du net en utilisant les outils traditionnels de régulation du marché, c’est-à-dire en leur faisant payer des taxes et en mettant en place des lois anti-trust ». Il préconise même d’accélérer le processus d’automatisation et d’analyse des données, car tout n’est pas négatif. Si les cancers pourront bientôt être dépistés grâce aux données, cela ne devrait pas se faire en donnant autant de pouvoir à des entreprises de la Silicon Valley ! Un système dans lequel les données appartiennent à la communauté permet à tout un chacun de se saisir de ces données pour en faire quelque chose, même au niveau local. E. Morozov préconise « un système hybride empruntant à la fois des éléments à la domanialité publique et à la propriété intellectuelle, tout en s’inspirant de certains mécanismes des licences libres ».
Cette hybridation entre protection personnelle et usage collectif se retrouve dans le point de vue du sociologue Antonio Casilli qui défend dans un article du Monde avec Paola Tubaro, l’idée que « la défense de nos informations personnelles ne doit pas exclure celle des travailleurs de la donnée ». Pour ces chercheurs « Nos informations ne sont plus ” chez nous “. Elles sont disséminées sur les profils Facebook de nos amis, dans les bases de données des commerçants qui tracent nos transactions, dans les boîtes noires algorithmiques qui captent le trafic Internet pour les services de renseignement. Il n’y a rien de plus collectif qu’une donnée personnelle. La question est donc moins de la protéger de l’action d’intrus qui cherchent à en pénétrer la profondeur que d’harmoniser une pluralité d’acteurs sociaux qui veulent y avoir accès. ». C’est pourquoi plutôt que la protection individuelle des données, Casilli et Tubaro défendent une négociation collective contre des services. Lionel Maurel et Laura Aufère développent cette approche dans un post très détaillé de S.I.Lex. Ces chercheurs prônent une protection sociale au sens large du terme, car « si les données sont produites dans le cadre d’activités assimilables à de nouvelles formes de travail, alors ce sont des mécanismes de protection sociale enracinés dans le droit social qu’il convient de déployer pour garantir les droits des personnes. ». Ils préconisent de se doter de moyens adéquats pour engager ces négociations dont les termes restent encore dictés par le cadre imposé par les plateformes. Dans cet article, repris d’ailleurs par Libération, les chercheurs dessinent les contours de ce nouveau droit social du 21e s. Jusqu’à présent, la protection des données était restreinte au niveau individuel. Comme le soulignent la juriste Antoinette Rouvroy et Valérie Peugeot de l’association Vecam, que ce soit pour l’obligation de consentement que pour la portabilité des données, aussi bien la CNIL que le RGPD se concentrent trop sur le niveau individuel. D’où l’importance de « mobiliser un nouvel imaginaire pour construire un cadre de négociation collectives sur les données ». 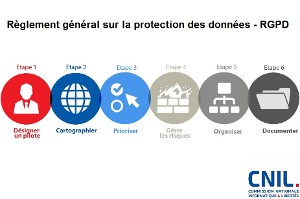
Rochfeld, Judith ; Farchy, Joëlle ; Forteza, Paula ; Peugeot, Valérie. - « Les internautes réclament un usage moins opaque et une maîtrise de leurs données personnelles ». Tribune. – Le Monde, 07/02/18
Loi données personnelles : dans l’apathie des débats, une envolée néo-libérale absurde ! - La Quadrature du Net, 07/02/18
Courgnaud-Del Ry, Martine. – Des services numériques communs émergent enfin sur tout le territoire. – Gazette des communes, 07/02/18
Guillaud, Hubert. – Pourquoi mes données personnelles ne peuvent pas être à vendre ! – Internet Actu, 06/02/18
Données personnelles : le projet de loi qui va mieux nous protéger. – La Dépêche, 06/02/18
Assemblée nationale. – Société : protection des données personnelles – Projet de loi déposé le 13 décembre 2017- discussion 06-08/02/18/Paula Forteza, Rapporteure.
Wiggleworth, Robert (FT). – Big data : les données numériques peuvent-elles révolutionner l’action politique ? – Nouvel Economiste, 06/02/18
Collectif. – Nos « données personnelles » nous appartiennent : monétisons-les ! - Le Monde, 05/02/18
Casilli, Antonio ; Jeanticou, Romain. – La domination des géants du numérique est-elle un nouveau colonialisme ? Entretien. – Télérama, 05/02/18
Abiteboul, Serge ; Dowek, Gilles. – « La propriété des données est une fausse bonne idée ». – Le Monde, 05/02/18
Maurel, Lionel ; Aufrère, Laura. – Pour une protection sociale des données personnelles. – S.I.Lex, 05/02/18
Nitot, Tristan. – Données personnelles et droit de vendre des organes humains. – Standblog, 02/02/18
Lévêque, Rémy. – « Facebook nous prend en otage ». – Usbek & Rica, 02/02/18
Parapadapis, George. – RGPD, de l’incertitude aux solutions pratiques. – Informatique News, 31/01/18
Revendre ses données « personnelles », la fausse bonne idée. – Mais où va le web ?, 29/01/18
Ertzscheid, Olivier. – Faut pas prendre les usagers des GAFAM pour des datas sauvages. – Affordance.info, 28/01/18
Pour une patrimonialité des données : Rapport. – Mes data sont à moi/Collectif data. – Génération libre.eu, 25/01/18
Naughton, John. – Who’s doing Google and Facebook dirty work?- The Guardian, 24/01/18
Casilli, Antonio ; Tubaro, Paola. – La vie privée des travailleurs de la donnée (Le Monde, 22/01/18) – Antonio A. Casilli
Mallat, Stéphane. – Sciences des données : leçon inaugurale (vidéo). – Collège de France, 11/01/18
Schmitt, Fabienne ; Madelaine, Nicolas. – Gaspard Koenig : « Chaque citoyen doit pouvoir vendre ses données personnelles ». – Les Echos, 07/01/18
Rey, Olivier ; Rouvroy, Antoinette. – Données, savoir et pouvoir (Table ronde). – PhiloInfo, décembre 2017 (vidéo).
Austen, Ian. – City of the Future? Humans, not technology, are the challenge in Toronto. – The New York Times, 29/12/17
Calimaq (Lionel Maurel). – Evgeni Morozov et le « domaine public » des données personnelles. – S.I.Lex, 29/10/17